Data is a valuable thing to have. Most of the times it is already out there, laying around in HTML pages or waiting to be requested by a js callback, in what may we can refer to as static and dynamic content, respectively.
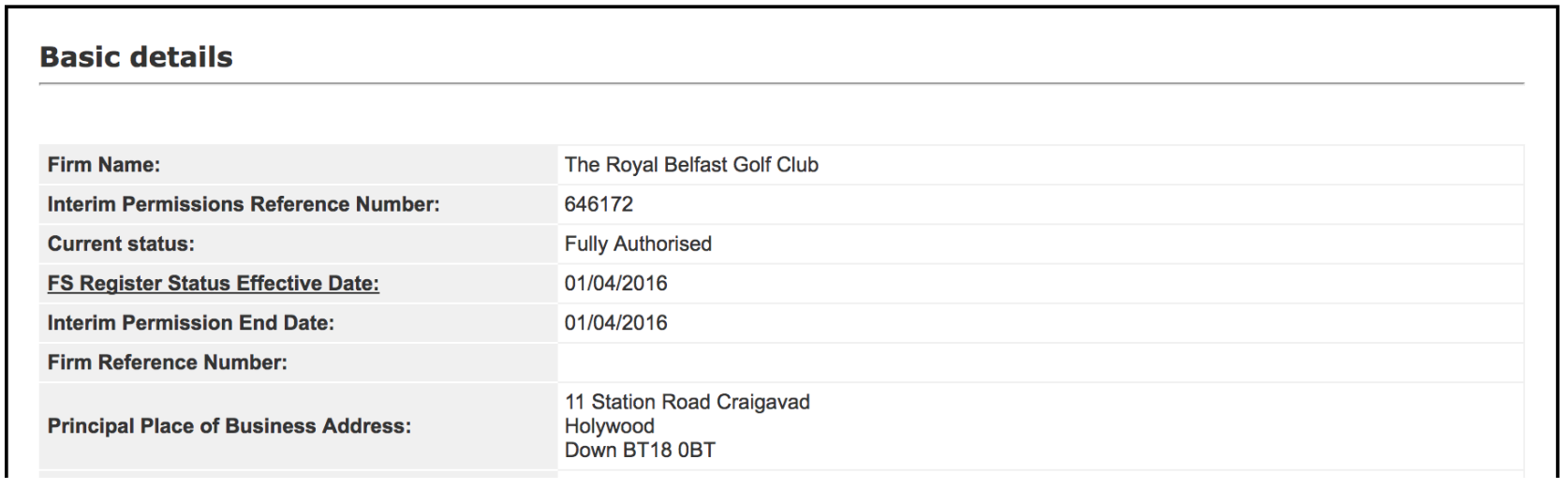
Lets suppose you need a database of companies that in the UK that are allowed to carry out consumer credit activities. To serve as an example, lets suppose we are interested in finding out if the Royal Belfast Golf Club in Irland is allowed to provide financial credit to its clients.
This data is public and available in the financial conduct authority
To help us parsing the HTML page we will need BeautifulSoup.
Lets create a new python project using the very convenient Python packaging tool Pipenv.
pipenv -threeNow install beautiful soup and requests (to help with the HTTP requests)
pipenv install beautifulsoup4 requests
The soup object provides a handler to our HTML page. We can use a simple API to easily navigate through the nested HTML tags and retrieve the information we want.
We can give it a look asking for its string representation print(soup)
Navigation through the structure is a simple task:
Accessing the text attribute will return the text contained in the BS element.
The find method will search and return the first element of the type passed as argument. findAll does the same but returns a list of every element contained in the element being called from.
With both methods we can provide a filter (dictionary) as second argument.
find(tag, filter)
Where filter can be something like:
filter = {"id" : "010101"}
If you have a massive amount of urls to crawl you will probably want to parallelize your work, so that you can have multiple threads working in parallel. We can easily achieve this by wrapping the previous logic into a function, and mapping it into a set of threads:
processes specifies the number of resources to be available in our pool. The data urls are divided by the threads, with each one applying get_basic_information to each element of its data chunk. company_dataset gathers all of the results in a list.
If local parallelisation is not enough, you might consider distributing the work into a cluster using a distributed processing engine.
The data we’ve already extracted is a start. However most of the times we need more details (if available). Suppose now that we are not only interested in the basic information, but that we are also interested in assessing which types of permissions are allowed to be performed by the Royal Belfast Golf Club.
This information is under the permissions tab.

However the information being displayed is dynamically loaded by a javascript routine once the user clicks in the permissions tab. It wasn’t present in the original HTML page.
In order to automate this process, our scrapper needs to be capable of invoking the specific javascript routine, wait for the content to be loaded, and then extract the information. Sometimes the AJAX request can be tracked down to something like:
easyAjax.example.com/ajax/search.json?parameter1=001¶meter2=100
However there are situations where the resulting javascript code will be machine-generated, thus intractable.
In the original link we can see the js code being processed once the user clicks the permissions tab.
<a href="#" onclick="if(typeof jsfcljs == 'function'){ ... }return false" class="makeover">Names</a>
<a href="#" onclick="if(typeof jsfcljs == 'function'){ ... }return false" class="makeover">Permissions</a>
<a href="#" onclick="if(typeof jsfcljs == 'function'){ ... }return false" class="makeover">Disciplinary History</a>
<a href="#" onclick="if(typeof jsfcljs == 'function'){ ... }return false" class="makeover">Waivers</a>
In essence what we want is automate the process of interacting with the website. For this we will need a headless browser, i.e. a web browser without a graphical user interface.
I recommend PhantomJS, due to its simplicity.
brew install phantomjs
All that we need now is a way to automate the actions that an user normally performs in a website. For this purpose we will use Selenium, a web browser automation tool with a simple Python interface.
Now that we have an arsenal of tools, we can build scrappers that don’t stop at nothing, even when confronted with dynamic content.
driver is a handler to our headless browser powered by PhantomJS. Selenium provides an API close to the one we were using with BS.
We have two analogous functions to the previous find and findAll: find_element_by_xpath and find_elements_by_xpath respectively.
From Selenium documentation:
driver.find_element_by_xpath("/html/body/form[1]") # 1
driver.find_element_by_xpath("//form[1]") # 2
driver.find_element_by_xpath("//form[@id='loginForm']") # 3
- Absolute path (would break if the HTML was changed only slightly)
- First form element in the HTML
- The form element with attribute named
idand the valueloginForm
Once we have our dynamic content loaded we can ask the current page source from the headless browser, lift it again to the BeautifulSoup context and keep working with the new content.
outerHTML = BeautifulSoup(driver.page_source, "html.parser")
The page_source attribute returns the current HTML in the PhantomJS context.
We have now one final detail to deal with. Once a javascript is made, there is no trivial way of knowing when the dynamic content as finished loading. The click method is thus asynchronous. A naive way of doing this would be to call time.sleep(x) after the call to click to make sure the content has finished loading. However there is no obvious value for x.
Fortunately Selenium provides an implicit wait, which makes the WebDriver constantly ask if the content is available, for a certain amount of time before raising an error.
driver.implicitly_wait(10) will raise an error if the new content is not available within 10 seconds.
With this set of tools you should be able to extract information regarding financial activity of any golf club, dynamically loaded content is required.