In a previous post we have discussed in some detail the design of a machine learning platform covering model training, serving, governance and observability.
We are now going to look with more detail to model serving:
- the different model consumption patterns;
- technical solutions to each one;
- comments on the additional complexity required by the solution to accommodate all the different patterns;
The Patterns
Online Stateless
The consumption is done on an event basis, hence the model needs to exposed behind a service, e.g. REST, gRPC. The consumer has the ownership of sending all of the necessary data for the inference operation as dictated by the API contract. Useful to obtain inferences for a single input or a batch of them. Acceptable response times are typically on the subsecond range. Each request is independent and therefore no state needs to be maintained.

For this consumption pattern, the service exposing the model needs to be operational on a continuous basis since the service does not know in advance when consumers are going to request an inference.
In terms of scalability we are primarily interested in responding to and increased number of individual consumers and not to increases in the volume of data being passed to the service; in this pattern we assume that the consumer is interested in obtaining inferences for one/small-batch of examples. More suitable patterns should be used if a particular consumer needs to obtain inferences for arbitrarily large datasets.
Online Stateful
This consumption pattern is required for more complex scenarios where the the consumer might require some level of interactivity with the model service.
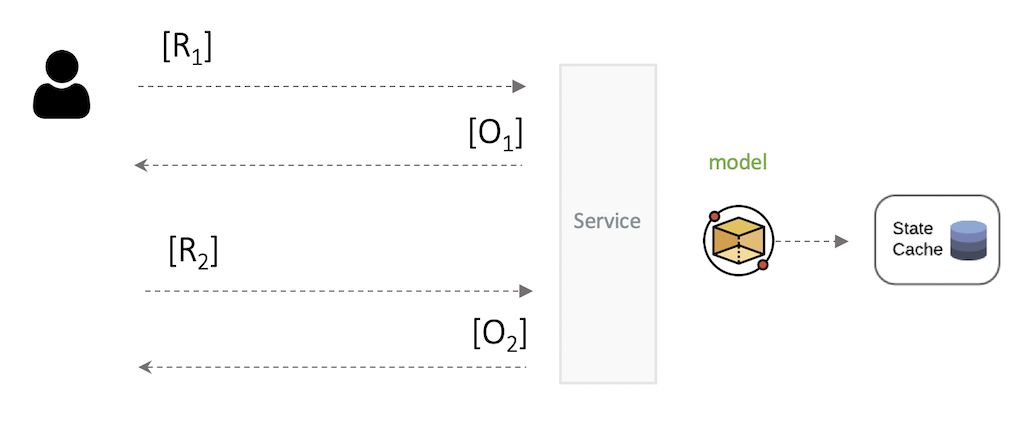
E.g.:
- Consumer
C1makes a call to a serviceSasking for a recommendation; - Service
Sresponds back with recommendationR1; - Consumer
C1is not satisfied and asks the serviceSto try again; - Service
Sanswers back with a second recommendationR2;
This scenario requires some form of state persistence across calls for the different consumers.
Offline in Batches
For scenarios where it is required to perform model inference at scale, an offline batch pipeline is the best option. Obviously because we can make use of transient infrastructure to serve the inference job. This pattern also differs from the online patterns with regards to the location of the data; for the online patterns the consumer has the responsibility to send the data; whilst for offline inference we expect the data to be located at a known storage.
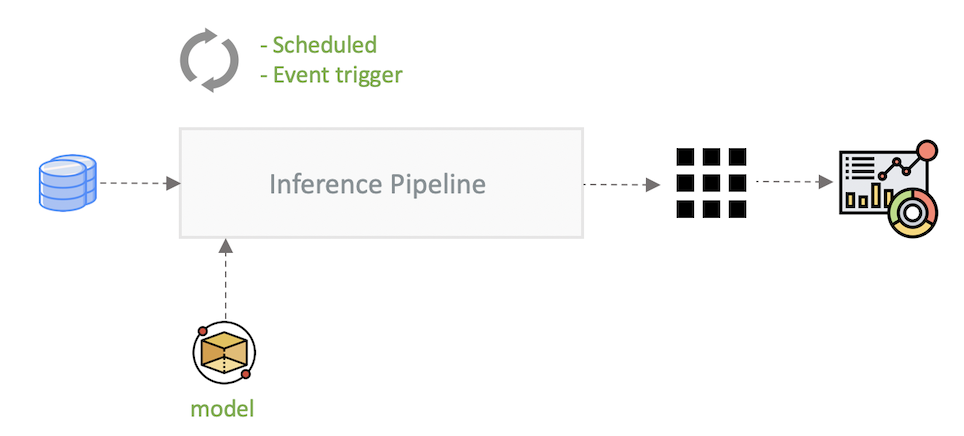
For smaller datasets, we could in theory have a consumer sending out a stream of batches to the online service but this extra logic would need to be implemented and maintained at the consumer side. Data processing frameworks like Apache Spark can easily distribute and collect the results.
The resulting inferences are then typically saved back to a storage system for later consumption by downstream applications, e.g. dashboards.
The Solution
The following diagram covers the deployment of a model to cover various consumption patterns.
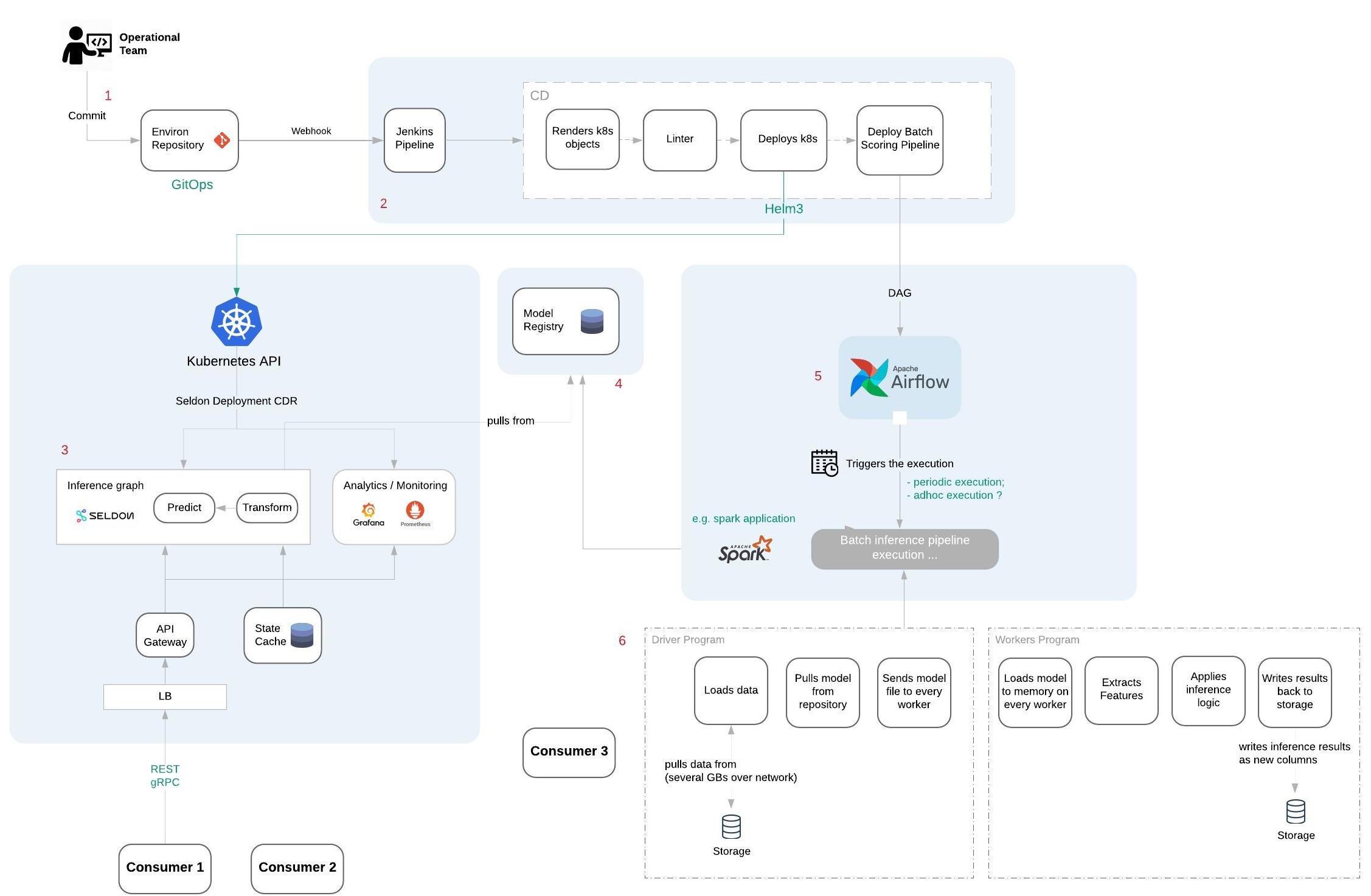
Assuming the GitOps is being used, whenever a new version of the model service is committed (1), the deployment against the infrastructure is performed in a declarative fashion.
A thin Jenkins Pipeline (2) is triggered that renders kubernetes objects, runs a linter and applies the changes.
For online serving (3) a Seldon Deployment object is deployed, consisting of:
- An inference pipeline, that wraps the model, behind a service;
- A real time dashboard with relevant metrics;
- (Optionally) an explainer to support model interpretability;
The model should be located at a model registry (4) that takes care of versioning and metadata management.
Seldon is a model serving framework that supports model deployment on a Kubernetes cluster. It allows for the creation of inference graphs, where each step runs as a different container.
Every graph has a model orchestration pod at the top with a standardized API contract for both REST and gRPC. When it receives a request (or a batch of requests) it then triggers the execution of the graph. The of the wiring between the steps is handled by Seldon.
It also leverages Kubernetes’s inherent scalability to create replicas of the service to cope with peaks in the number of requests.
In parallel to this deployment, a offline batch pipeline (6) should also be available, to perform the following tasks:
- read a batch of the data, e.g. one month;
- extract relevant features from the data;
- uses one or more models to score data offline;
- writes the results back to storage;
Notes that this might require some integration work if model wasn’t trained via Spark API, as the libraries with the relevant APIs to load the model into memory must be available on every node;
This pipeline exposes the model inference results as additional columns that can be posteriorly consumed by other applications; The deployment of the batch pipeline must also be supported by orchestration logic (5) to trigger the execution of the pipeline with the right configurations.
Final Comments
Having to support more than one pattern has some disadvantages:
- The observation/monitoring capability to measures things like data drift or prediction bias might need to be replicated in both the online and the offline cases, which can sometimes involve duplicated work;
- The same can be said with regards to model interpretability / explainability;